
Read through the summarized points below carefully. As a last exercise, continue with the mixed exercises (link below), which summarize everything that you (should) have learned today.
Error propagation
- All experiments contain experimental error.
- For many analytical instruments (glassware, balance, ...), the error is shown on the equipment.
- The error in a final answer can be calculated by using error propagation rules.
- Errors for multiplication and division have to be calculated relatively, because these operations often involve different quantities.
The normal distribution
- Many experimental errors are normally distributed.
- They can be characterised by a mean value and a standard deviation.
- The mean describes the location.
- The standard deviation describes the spread around the mean.
- Random errors are related to the standard deviation.
- Systematic errors are related to the difference between the mean and the (unknown) true value (the bias).
Prediction & Confidence intervals
- The larger the standard deviation (the spread around a central value), the wider a prediction interval will be.
- A 95% prediction interval will contain the next experimental value with a probability of 95%.
- A crude estimate of a 95% prediction interval is the mean plus or minus twice the standard deviation.
- A crude estimate of a 99% prediction interval is the mean plus or minus three times the standard deviation.
- Confidence intervals are narrower than their corresponding prediction intervals, since errors cancel out.
- The standard deviation of the mean is the standard deviation of the individual values divided by the square root of the number of measurements.
Least squares regression
- The linear relationship between two variables
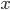 and
and 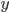 can be described by the intercept
can be described by the intercept 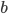 and the slope
and the slope 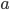 of the optimal straight line.
of the optimal straight line. - Standard errors for the intercept with the axis and slope can be calculated, and therefore confidence intervals too.
- It is assumed that the error in is much smaller than the error in .
- Residuals are assumed to be independent and normally distributed with constant variance.
- Regression lines may be used for calibration: the calibration line is set up using a set of calibration samples and the concentration in an unknown sample can be predicted.
- Regression lines can be used to compare methods.
As a final test, prepare yourself for the mixed exercises.